
In my last post introducing Barazo, I said I’d cover trust and identity next. Turns out this is less about Barazo specifically and more about a problem hitting every online community right now.
The slop problem
Generated content that exists to fill space, game algorithms, or fake engagement. Wordvomit that doesn’t add any value, and it’s getting worse fast.
Slop and “gaming the algorithms” existed before AI, but volume exploded when content generation costs neared zero (thx LLMs!) and the tools to detect it fall behind.
Not all AI-generated content is bad, but the ratio of generated noise to genuine signal is climbing in every community I participate in (hello LinkedIn, YouTube, Reddit and microblogging platforms). And then there’s content pretending to be human when it’s not. I’m fine with getting an AI answer on a product forum that’s trained on that product and can instantly get me on the right path. I just want to move forward and don’t care who gave the answer. But in many other contexts, the source does matter.
I’ve run communities on Slack, Discord, Vanilla, and self-hosted forums (remember vBulletin and phpBB? #YesImOld). The moderation load has changed: where the old playbook (spam filters, manual review, rate limiting) was built for human-speed abuse, this completely breaks down when one person with a script can flood your forum with plausible-looking posts faster than your mod team can read them.
Why traditional moderation fails
Most community platforms handle moderation at the content level: you flag a post, review a post, remove a post, repeat.
Against AI slop, this is a losing game.
Volume is one part: a human moderator can review maybe 100 posts per hour, while a slop generator can produce 100 posts per minute. The math doesn’t work.
Then there’s the quality: where early AI spam was obviously fake, current slop is harder to spot. It uses correct grammar, references real concepts, and sometimes even makes valid points. The tells are subtle, and I’d expect LLMs to only get better at this since that’s quite literally what they’re being designed to do.
And the persistence:
- Ban an account, they create another.
- IP blocks? VPN.
- Email verification? Disposable addresses.
Every barrier you add costs real members more than it costs bad actors. They update their scripts once and move on.
Content-level moderation is necessary, but nowhere near enough on its own.
Account-level trust helps (but only locally)
The bigger social platforms have already moved beyond content-level moderation: instead of evaluating each post in isolation, they look at the person posting it. Account age, contribution history, how the community responded to their previous posts. Stack Overflow’s reputation system, Reddit’s karma, Discourse’s trust levels all work this way.
Discourse probably has the most thought-out system here. Five trust levels (TL0 through TL4), where new users start sandboxed (limited links, images, and posting frequency) and earn privileges by actually reading and participating. TL3 requires months of consistent engagement and is revocable if you go inactive. They even added LLM-based spam detection in late 2024 after Akismet stopped catching AI-generated content, scanning posts from low-trust users to check whether they’re actually engaging with the thread or just producing filler.
And it works, IF you have scale. A platform like LinkedIn or Reddit has millions of users and tons of activity, so a three-year-old account with hundreds of helpful answers gets treated differently than one created five minutes ago. A mid-sized Discourse forum with a few thousand active members generates enough signal for the trust levels to be meaningful too.
On smaller forums you don’t have that luxury. When most of your active members are relatively new and have a handful of posts, account-level trust gives you almost no signal. You’re basically guessing.
The big platforms don’t need cross-platform trust because they have enough internal data, but smaller communities would benefit a lot from knowing that a new member already has a solid track record somewhere else.
And the current setup creates a massive opening for AI slop: if everyone starts at zero everywhere, there’s no way to tell a new genuine member from a new bot account.
Portable track records
What if your contribution history could follow you across communities? A verifiable record of what you did, where, and when… that you control instead of it being locked inside one platform’s database.
This idea isn’t new: Klout tried it from 2008 to 2018, aggregating social media activity into a single 0-100 influence score. Got acquired for $200M and then shut down. The problems: an opaque algorithm that was trivially gamed (follower count was basically the score), a single context-free number that meant nothing (Goodhart’s Law in action), and dependency on platform APIs that could cut access anytime. Kred, PeerIndex, and Skorr tried the same model and failed the same way.
The lesson imho: a single score across contexts is meaningless. What someone contributed only means something within the context where the action happened. A “reputation score: 742” tells you nothing about whether someone is helpful in a Shopware forum or active in an ecommerce community. Those are different things.
So what I’m building works differently: activity data stays with each community; what travels between communities are contribution records and context labels, not a score. Each community decides how to interpret them.
When a member joins a new community, their history from other communities is visible. The content stays local, but the activity record travels: what they contributed, how the community received it, and whether they were flagged for abuse.
So what changes?
Zero trust by default. First posts go through review, and as contributions prove genuine, restrictions loosen automatically. At Spryker we built something similar (new-account trust ramps), and it worked well even without cross-community data.
But established members with verified contributions across three communities don’t need their posts pre-screened. They’ve earned that through behavior, not time.
The big one: slop accounts can’t fake history. You can generate a thousand plausible forum posts. You can’t fake two years of helpful contributions that other real people actually engaged with across independent communities. This is the bit that makes the biggest difference, I think.
And bad behavior follows you. Get flagged for abuse in one community, that information is available to other communities as signal, not as an automatic ban. Each community still makes its own moderation decisions.
How this works on AT Protocol
I’m building Barazo on AT Protocol because it makes portable contribution history possible without a central authority.
Decentralized identity. Your AT Protocol identity (your Bluesky handle) isn’t owned by any single application, and you can move it between providers. Your track record is tied to an identity you control, not an account some company controls.
User-owned data. When you post in a Barazo forum, that content is written to your Personal Data Server (PDS). Every topic, reply, and reaction is a record on your PDS. Barazo’s backend indexes a copy for fast browsing and search, but the PDS is the source of truth. No platform can inflate or erase your contributions because they don’t control the source data.
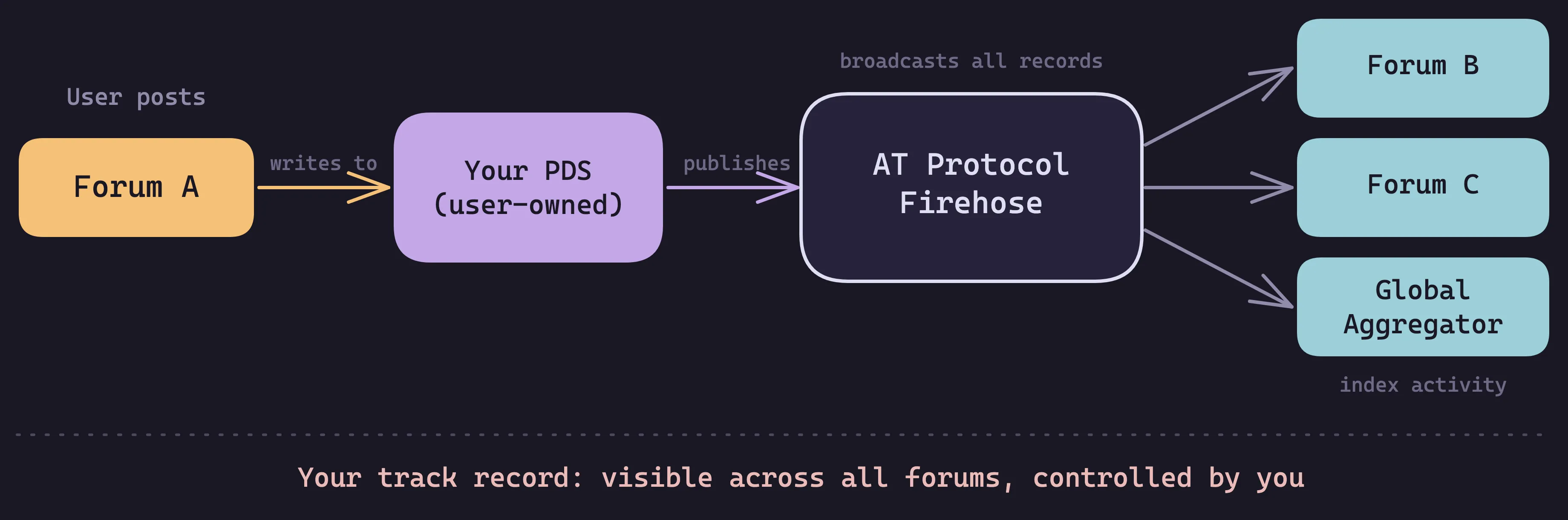
AT Protocol’s firehose broadcasts all public PDS records, and that’s what makes cross-community track records possible: when you react to a post in Forum A, that reaction propagates through the firehose and any other forum’s backend can index it. The raw activity data (posts, replies, reactions you gave and received) is accessible to the whole network, not locked in one forum’s database.
Now you might wonder: if users own their PDS, can’t they fake the inputs? They could write fake reaction records, sure. But your track record doesn’t come from your own reactions, it comes from how other real people responded to your contributions, and those reactions live on their PDS, not yours. Creating fake accounts to upvote yourself doesn’t work either: the trust algorithm (EigenTrust) that runs internally for abuse detection only propagates trust from accounts that are themselves already trusted, and cluster detection catches coordinated groups.
Show your work. I’ve been thinking about this a lot, and computed scores are the wrong abstraction for displaying trust: a number like 0.72 means nothing to a human, and the more real you make a score, the more it can be used to exclude people.
That’s counterintuitive: we want professional contributions to matter, but a single number claiming to represent someone’s professional worth is structurally a social credit system regardless of how transparent the algorithm is. 😅
So profiles display descriptive activity data: what you did, where, when, and how the community received it. Humans draw their own conclusions from the evidence. EigenTrust runs internally for sybil detection and spam filtering, but its output is never surfaced to users as scores, tiers, or ranks.
Multiple signals. The activity data covers how others responded (genuine engagement vs. ignored posts), consistency over time, and diversity across communities. Gaming one type of activity is easy, but faking all of them simultaneously across independent communities… much harder.
Each forum instance decides how much weight to give external activity: a technical community might care most about contribution quality in similar communities, while a local community might prioritize local participation. The activity data is shared; the interpretation is local.
And contributions aren’t permanent fixtures: old activity matters less than recent ones, and if someone had a bad period, sustained good behavior rebuilds trust. People change, and the system should reflect that.
Beyond forums
AI slop is hitting every platform: forums, social media, comment sections, all of it. And the trust problem (starting from zero everywhere, contribution history locked in silos) exists across the entire internet.
What I’m building with Barazo is a starting point, but the more I work on this, the more I see it going beyond community forums. Think about professional identity: your LinkedIn profile is basically self-reported claims with endorsements from people who clicked a button. What if your professional identity was backed by verifiable contributions from actual communities where people engaged with your work? A track record of consistently helpful answers in your field, across independent communities, verified by real people. That’s harder to fake than a self-reported “10 years of experience.”
AT Protocol’s open nature means any application can participate. A contribution to an open source project, a helpful answer in a forum, expertise demonstrated in a professional community… these could all feed into a portable track record that travels with your identity. Contextual activity data, published as open records that any application can read and interpret.
I’m working on pieces of this that go beyond Barazo itself. The protocol infrastructure already exists, and the question is building the right layers on top.
What this doesn’t solve
Cross-community track records are harder to game than single-platform systems, but coordinated groups could still try to inflate each other’s activity. The multi-signal data, trust seed propagation, and cluster detection help. Sybil clusters (fake accounts that only interact with each other) get near-zero trust because trust can’t propagate through a cluster with no genuine connections to the legitimate network. No system is bulletproof though.
A risk I keep coming back to: the line between “show your work” and social credit scoring is thinner than it looks. If you’ve seen Black Mirror’s “Nosedive” (the one where everyone rates every interaction and your score determines your access to housing, flights, and social circles 😅), you know the dystopian version. The more verifiable and cross-platform you make contribution data, the closer you get to that world. Choosing to display activity data instead of scores is a design guardrail, not a permanent solution. I don’t have a clean answer here, and I’m skeptical of anyone who claims they do. I’d rather figure it out in the open than pretend the risk doesn’t exist.
Privacy is a real tradeoff: your activity in one community becomes visible to others. That’s the point… but it’s also a fair concern. The system needs controls for what you share, where, and with whom. Still working through the right defaults here.
Cold start is another one: not everyone has community activity from day one. Other signals help (cryptographically verified identities, social graph connections, account age) and fill the gap until contributions accumulate. A newcomer’s profile is simply sparse… it fills in as they participate.
And even with rich activity data, communities still need human moderators making judgment calls. Track records add signal, they don’t replace human decisions.
Then there’s adoption: a system like this is only as useful as the network participating in it. One forum’s activity data is a data point; a thousand forums’ data (plus professional networks, social platforms, and other applications reading and contributing to the same layer) is an ecosystem. Getting there takes time… same chicken-and-egg problem every protocol faces.
Where this is going
AI-generated content is only going to increase. Within a year or two, I think the difference between human-written and AI-generated text will be nearly undetectable by automated tools.
Content-level moderation can’t win this arms race alone. Verifiable track records that carry real weight across platforms, tied to identities that people actually invest in, make it structurally unattractive to produce slop.
The current internet architecture (isolated platforms, siloed identities, starting from zero everywhere) was built before AI content generation existed. It doesn’t fit a world where content is cheap and trust is scarce. We need trust infrastructure that works across the open web, beyond individual platforms.
I’d rather build something that works for the world we’re actually living in than keep patching what we have.
Barazo is open source and the trust system is being built in the open. If you’re working on similar problems or have thoughts on this, I’d like to hear from you.
What’s your community’s strategy for dealing with AI-generated content? And does a portable track record sound like something you’d actually use?